В предыдущей части рассмотрено, как ошибка оценки базовой (априорной) вероятности приводит к ошибкам. Часто же проблема кроется не в оценке вероятностей, а в учёте свидетельств, которые могли бы изменить наши убеждения.
Для иллюстрации этого типа ошибок перепишем формулу Байеса немного иначе. Исходная формула выводит вероятность основной гипотезы H с учётом свидетельства D:

Разумеется, можно посчитать и вероятность противоположной гипотезы ~H с учётом новых данных D. Это лишь вопрос переобозначения:

Поделив левые и правые части обеих равенств, приходим к одной из форм теоремы Байеса (ещё её называют “odds form”, “соотношением шансов”):

- P(H/D) / P(~H/D) — отношение вероятностей истинности основной и противоположной гипотез с учётом новых данных;
- P(D/H) / P(D/~H) — отношение оценок правдоподобия новых данных с точки зрения основной и противоположной гипотезы. Ещё можно это назвать отношением уверенностей, с которыми новые данные предсказываются основной и противоположной гипотезами;
- P(H) / P(~H) — отношение вероятностей истинности основной и противоположной гипотез вообще, ещё до новых данных.
Словами это можно выразить примерно так: чем увереннее противоположная гипотеза предсказывает событие И чем меньше ей доверяли до эксперимента, тем больше вероятность истинности противоположной гипотезы, если событие всё же случилось.
Часто при оценке значимости, весомости свидетельства (P(D/H) / P(D/~H)) люди недооценивают необходимость учёта знаменателя на тот случай, если основная гипотеза неверна.
Все больше исследований показывают, что недооценка того, что данные могут свидетельствовать в пользу противоположной гипотезы, воистину вездесуща. Показателен следующий эксперимент. Испытуемых просили представить, что они обследуют пациента с красной сыпью на теле. Им предложили четыре вида сведений и предложили выбрать те, что важны для постановки правильного диагноза вымышленной болезни Digirosa:
- процент людей, больных Digirosa;
- процент людей, не больных Digirosa;
- процент людей, больных Digirosa и имеющих на теле красную сыпь;
- процент людей, не больных Digirosa и имеющих на теле красную сыпь.
Легко видеть, что эти сведения соответствуют четырём элементам формулы Байеса: P(H), P(~H), P(D/H) и P(D/~H). Хотя P(D/~H) (процент людей, не больных Digirosa и имеющих на теле красную сыпь) очевидно необходим при постановке диагноза, 48.8% испытуемых не учли этой информации — те, кто не болен Digirosa и имеет на теле красную сыпь, казались не относящимися к делу.
Важность P(D/~H) часто кажется контринтуитивной. Необходимо научиться учитывать её или вы так и будете её игнорировать. Вот ещё один пример, в котором необходимость учёта P(D/~H) кажется странной даже после предупреждения.
Представьте, что вы готовитесь к встрече с Давидом Максвеллом. Вам необходимо оценить, с какой вероятностью он является профессором университета. Вы получаете ту или иную информацию для размышлений.
Шаг 1. Вам сообщили, что Давид Максвелл был на приёме, на котором из 100 присутствовавших 25 были профессорами университетов, а 75 бизнесменами. Вопрос: какова вероятность того, что Давид Максвелл профессор университета?
Шаг 2. Вы узнали, что Давид Максвелл состоит в престижном клубе. 70% профессоров, бывших на приёме, являются членами этого клуба. 90% бизнесменов с того же приёма также являются членами клуба. Вопрос: какова вероятность того, что Давид Максвелл профессор университета?
На первом шаге всё просто — вероятность 0,25. Во втором шаге имеется небольшая тонкость. Кажется, что раз больше половины профессоров состоят в клубе, то вероятность того, что Давид Максвелл профессор, следует увеличить. Это и есть игнорирование свидетельства P(D/~H). На деле же принадлежность к клубу более характерна для бизнесменов. Тем самым вероятность того, что Давид Максвелл профессор, надо не увеличить, а уменьшить. Разберём второй шаг подробнее:
- шансы, что Давид Максвелл профессор, до второго шага:
0,25 / 0,75 = 0,333;
- отношение правдоподобия с учётом новых данных:
0,70 / 0,90 = 0,777
- шансы, что Давид Максвелл профессор, на втором шаге:
0,777 * 0,333 = 0,259
Формальные вычисления согласно теореме Байеса также указывают на уменьшение вероятности того, что Давид Максвелл профессор, с 0,25 на первом шаге до 0,206 на втором шаге: (0,70 * 0,25) / (0,70 * 0,25 + 0,90 * 0,75) = 0,206.
В эксперименте автора лишь 42% испытуемых уменьшили свою оценку вероятности на втором шаге. Остальные не учли, что более высокое значение P(D/~H) “перевешивает” значимость P(D/H).
Ещё один пример того же самого, но иначе поданного. Вообразите, что вы встречаетесь с Марком Смитом. Вам необходимо оценить, с какой вероятностью он является профессором университета. Вы снова получаете ту или иную информацию для размышлений.
Шаг 1. Вам сообщили, что Марк Смит был на приёме, на котором из 100 присутствовавших 80 были профессорами университетов, а 20 бизнесменами. Вопрос: какова вероятность того, что Марк Смит профессор университета?
Шаг 2. Вы узнали, что Марк Смит состоит в престижном клубе. 40% профессоров, бывших на приёме, являются членами этого клуба. 5% бизнесменов с того же приёма также являются членами клуба. Вопрос: какова вероятность того, что Марк Смит профессор университета?
В этой задаче на первом шаге всё просто — вероятность 0,80.
На втором шаге отношение правдоподобия намного больше единицы (0,40/0.05) и P(D/H) мало (0,40). Кажется разумным пренебречь P(D/~H) как очевидно малым, даже несмотря на то, что оно должно уменьшать вероятность того, что Марк профессор университета. На деле байесианское вычисление показывает, что эта вероятность с 0,8 на первом шаге возрастает до 0,97 на втором: (0,40,8)/(0,40,8+0,05*0,2)=0,97. Тем не менее, лишь 30% испытуемых попытались на втором шаге _увеличить_ оценку вероятности.
Таким образом, любая переоценка от шага 1 к шагу 2 должна учитывать P(D/~H). Совсем необязательно точно всё подсчитывать, достаточно указать в верном направлении — вот суть байесианского мышления.
Игнорирование противоположной гипотезы — знаменателя в отношении правдоподобия — не просто ошибка. Во врачебной практике бывает жизненно необходимо помнить про противоположные версии диагнозов. Вся наука держится на том, чтобы принимать в расчёт одинаково как “за”, так и “против”.
Вот ещё пример: предположим, у вашей сестры есть машина, купленная пару лет назад, марки то ли X, то ли Y, вы не помните точно. Вы помните, что она проезжает 25 миль на одном галлоне бензина и ещё ни разу не ремонтировалась. Вы знаете, что:
- 65% машин марки X проезжают 25 миль на одном галлоне.
Доступны также следующие сведения:
- % машин марки Y, что проезжают 25 миль на одном галлоне;
- % машин марки X, не требовавших ремонта в первые два года эксплуатации;
- % машин марки Y, не требовавших ремонта в первые два года эксплуатации;
Вопрос: если вы можете получить только одно из этих трёх сведений, что вы выберете, чтобы уточнить, какой марки машина вашей сестры?
Разберём задачу подробно:
- гипотеза H1 — машина марки X;
- гипотеза H2 — машина марки Y;
- D1 — диагностический признак “машина проезжает 25 миль на одном галлоне”;
- D2 — диагностический признак “машина не требует ремонта в первые два года эксплуатации”.
У нас есть один кусочек сведений, P(D1/H1), какой процент машин марки X проезжает 25 миль на одном галлоне.
Возможны два отношения правдоподобия: P(DI/Hl)/P(Dl/H2) и P(D2/HI)/P(D2/H2). Так как мы не можем получить оба, то разумно суметь вычислить полностью хотя бы одно и запросить P(Dl/H2), узнав, какой процент машин марки Y проезжает 25 миль на одном галлоне. Если этот процент будет отличаться от известных нам 65%, у нас появится пища для содержательного размышления.
Выбор выглядит ясным, но для неподготовленного человека он совершенно не очевиден. Эксперименты показали, что большинство (60,4%) желает уточнить P(D2/H1) процент машин марки X, не требовавших ремонта в первые два года эксплуатации. Это совершенно бесполезная информация, так как мы не можем узнать P(D2/H2). Без знания того, какой процент машин марки Y не требует ремонта в первые два года, полученную информацию невозможно использовать.
Сильное беспокойство вызывает то, что схожие результаты дал аналогичный эксперимент со студентами старших курсов медицинских вузов. Они пытались диагностировать тропическую болезнь типа A или B. Им сообщили вероятность P(симптом1/болезнь-A) P(симптом1/болезнь-A) и предложили на выбор одно из трёх сведений: P(симптом1/болезнь-B), P(симптом2/болезнь-A) или P(симптом2/болезнь-B). Ясно, что лишь первое из них давало возможность сравнить шансы, но 69.3% медиков-старшекурсников не смогли это увидеть.
Тенденция игнорировать иные возможные объяснения особенно ярко проявляется в широко известном “эффекте Барнума” (Барнум, знаменитый циркач, известен фразой “Дураки рождаются ежеминутно”). Часто на подготовительных курсах психологии преподаватель собирает образцы почерков всех учащихся и через неделю раздаёт “личные персональные уникальные анализы” почерка, составленные из общих фраз. Обычно учащиеся высоко оценивают точность подобных “анализов” — от 7 до 9 баллов по 10 баллов. Когда их просят сравнить описания, они бывают ужасно ошеломлены, увидев у соседей то же описание, что у себя. Именно эффект Барнума лежит в основе мифов о точности астрологии и тому подобных псевдонаук.
Если приглядеться к причинам этого, то мы увидим нашего старого знакомого — игнорирование P(D/~H). Люди неявно оценивают вероятность того, что описание “обычно вы открыты и дружелюбны, но иногда замкнуты и неразговорчивы…” относится к ним и оценивают её как высокую. Более формально, высокой оценивается вероятность
P("вы открыты и т.д."/"это описание сделано для меня лично")
Это, разумеется, не отношение правдоподобия. Это всего лишь P(D/H). Чтобы оценить шансы правдоподобия гипотез, необходимо знать P(D/~H), то есть
P("вы открыты и т.д."/"это описание сделано для всех людей вообще")
Конечно, мы немедленно увидим, что эта вероятность точно так же высока. Описание “вы открыты и т.д.” настолько размыто, что применимо практически к каждому, кто готов узнать в нём себя. Таким образом, отношение правдоподобия
P("вы открыты и т.д."/"это описание сделано для меня лично") / P("вы открыты и т.д."/"это описание сделано для всех людей вообще")
всегда равно примерно единице. Согласно формуле
(шансы истинности гипотезы после наблюдения) = (отношение правдоподобия) * (шансы истинности гипотезы до наблюдения)
сколько бы данных ни было собрано, при отношении правдоподобия, примерно равном единице, шансы истинности гипотезы не изменятся — свидетельства не влияют на них! Иными словами, данное свидетельство не несёт ничего нового — это очевидно, если обратить внимание на P(D/~H).

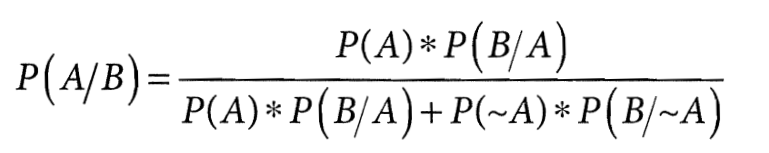
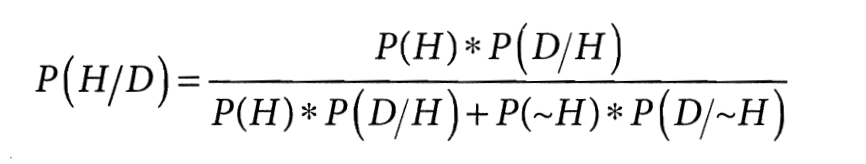
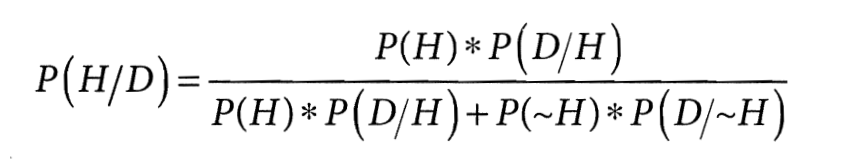
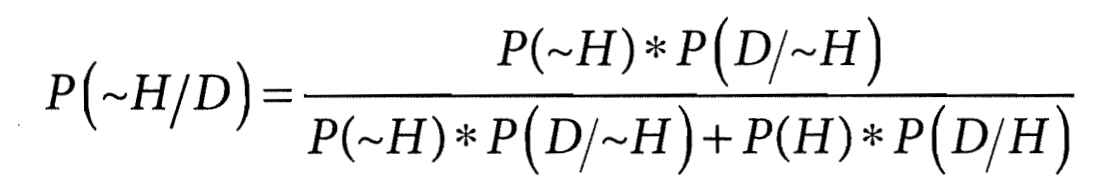
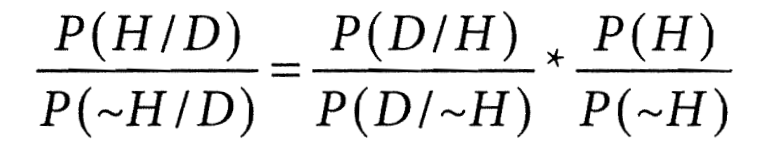

Add new comment